Listen and Translate
Task Description
- Given a Taiwanese audio signal, select the most possible Chinese translations from the given options.
Preprocessing
- Use
gensimto implement word embedding - Do downsampling to MFCC audio features
- Add noise, negative sampling to audio features
Models
1. LSTM model
- Kaggle accuracy: 0.246
2. Bidirectional LSTM model
- accuracy: 0.4
3. Simple baseline model: Use an RNN model to predict the first word
- accuracy: 0.328
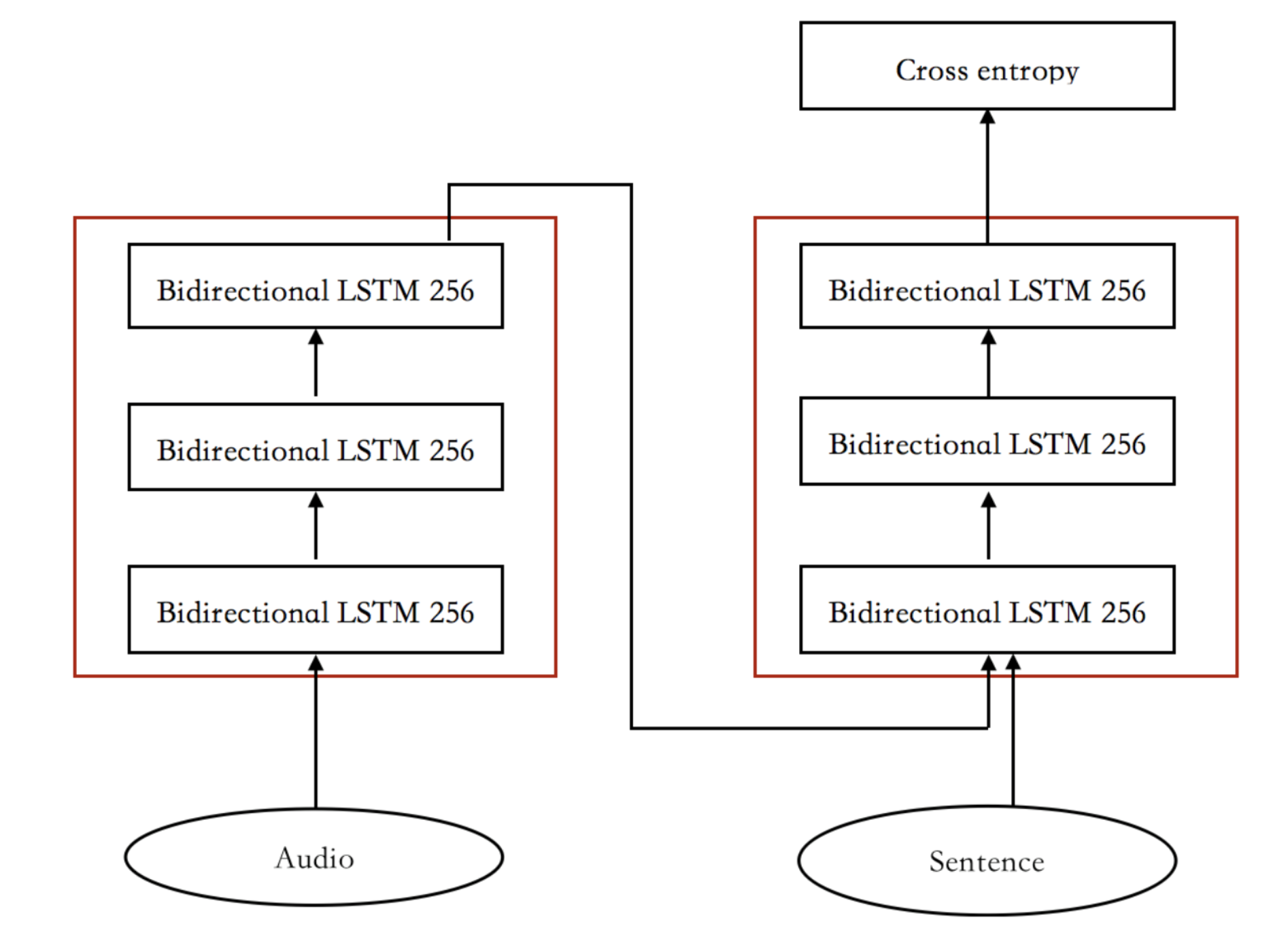
4. Strong baseline model: Sequence to sequence
Encoder: MFCC $\rightarrow$ Bidirectional RNN
Decoder: RNN $\rightarrow$ encoder initial state + attention (LuongAttention)
- accuracy: 0.724
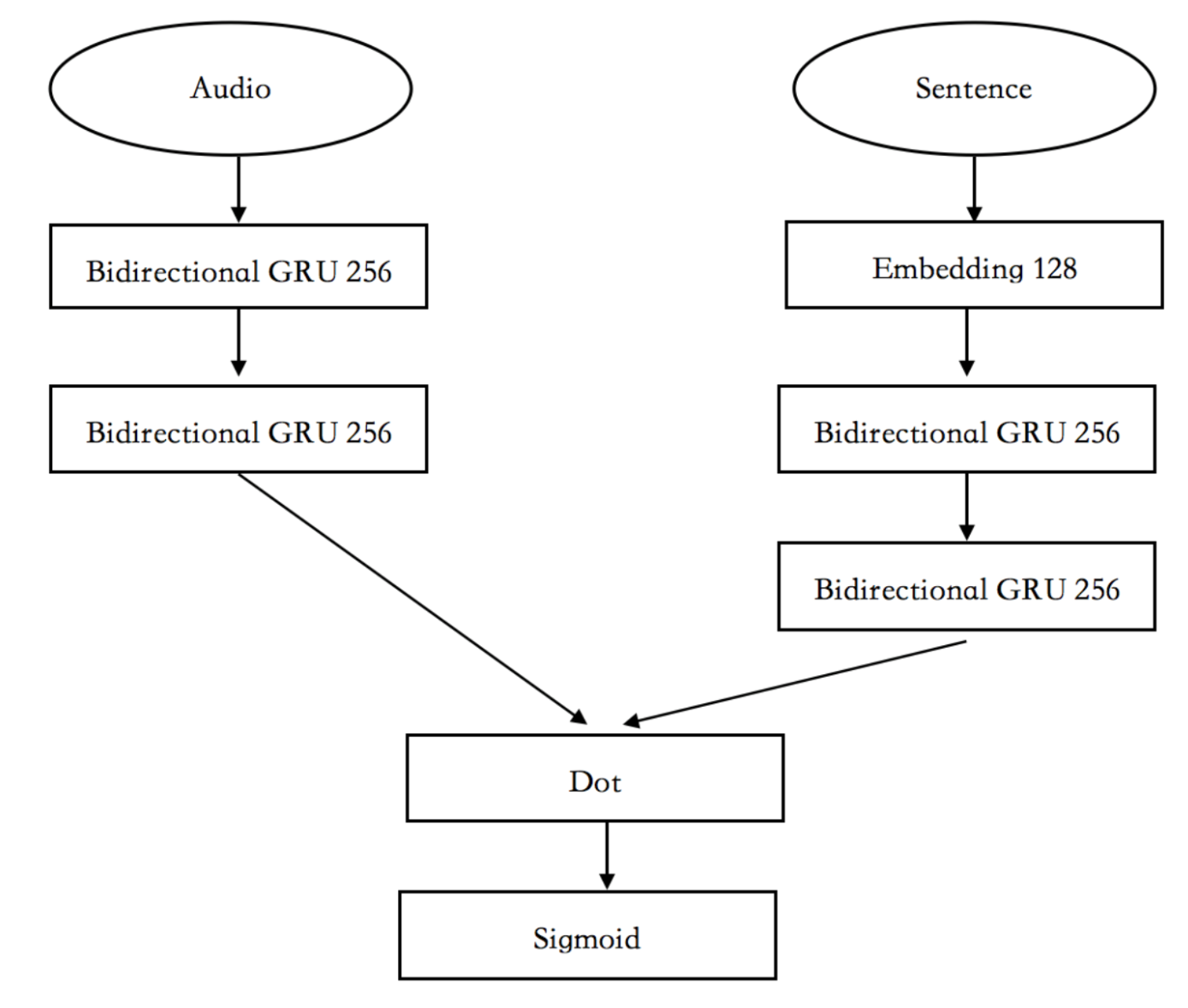
5. Best model: Retrieval model
Encoder (MFCC): Bidirectional GRU
Encoder (caption): embedding layer + Bidirectional GRU
Similarity: inner product + sigmoid
- accuracy: 0.84(single), 0.864(ensemble)
Result
- Achieved 8/86 (Top $10\%$) rank in the Kaggle competition