Movie Rating Problem
Movie type estimation
As training the matrix factorization model, we can obtain user and movie embedded vectors, which represent some features about movies/users and relationships between them, with arbitrary dimensions. I use a 500-dimension vector to represent a movie/user. With TSNE to reduce dimension and K-means to classify the movies (about the original vectors) into 5 categories, I get the following results:
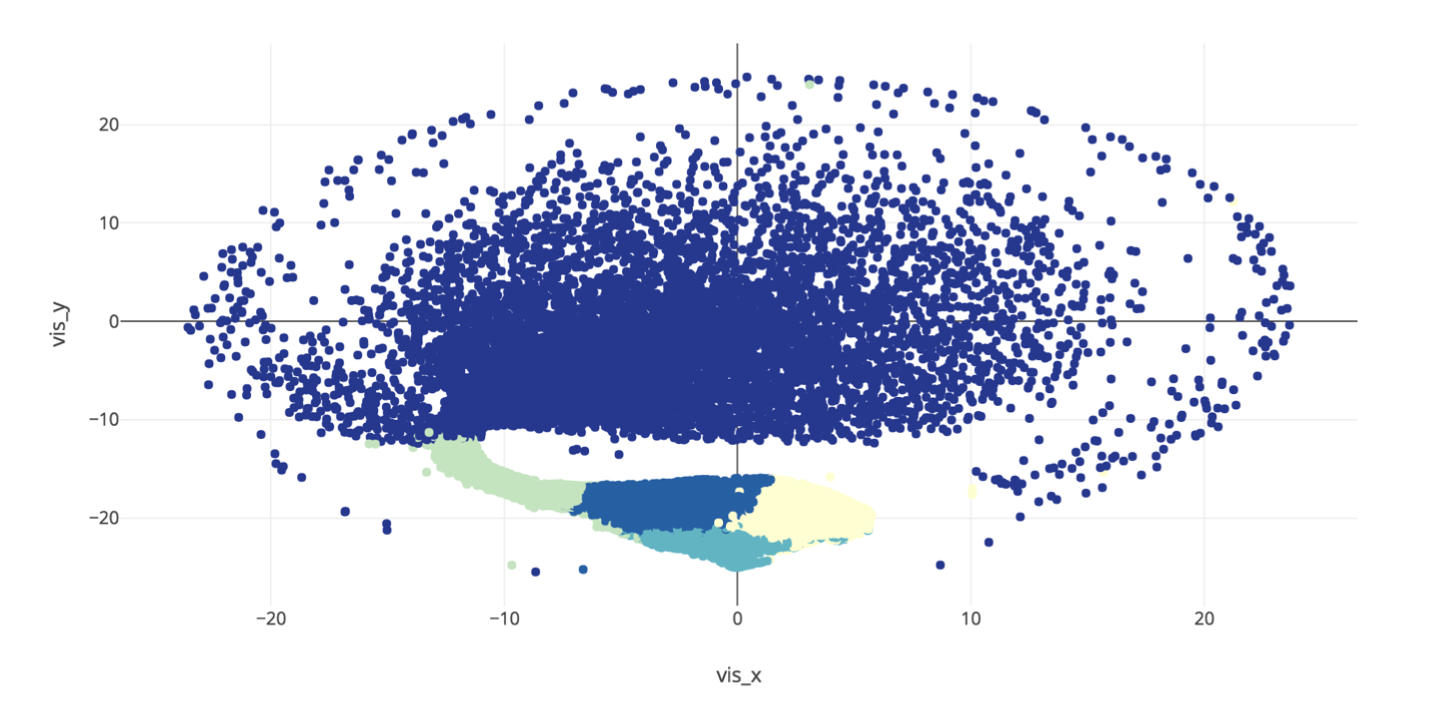 Figure 1. Visualization of Movie Embedding Layer through TSNE and K-means
Figure 1. Visualization of Movie Embedding Layer through TSNE and K-means
The plot shows that the K-means categories might be underestimated, so the blue area is too big for us to learn information. I also count the percentage of genres appearing in each category (the following figure), it shows that the K-means categories can barely identify the genres either. The interesting thing here is that the trend in Category 2 is quite different from the others. I find that this Category is more latest movies than the other categories and that its genres are more acceptable by universals, e.g. Adventure, Action, Comedy, Sci-Fi.
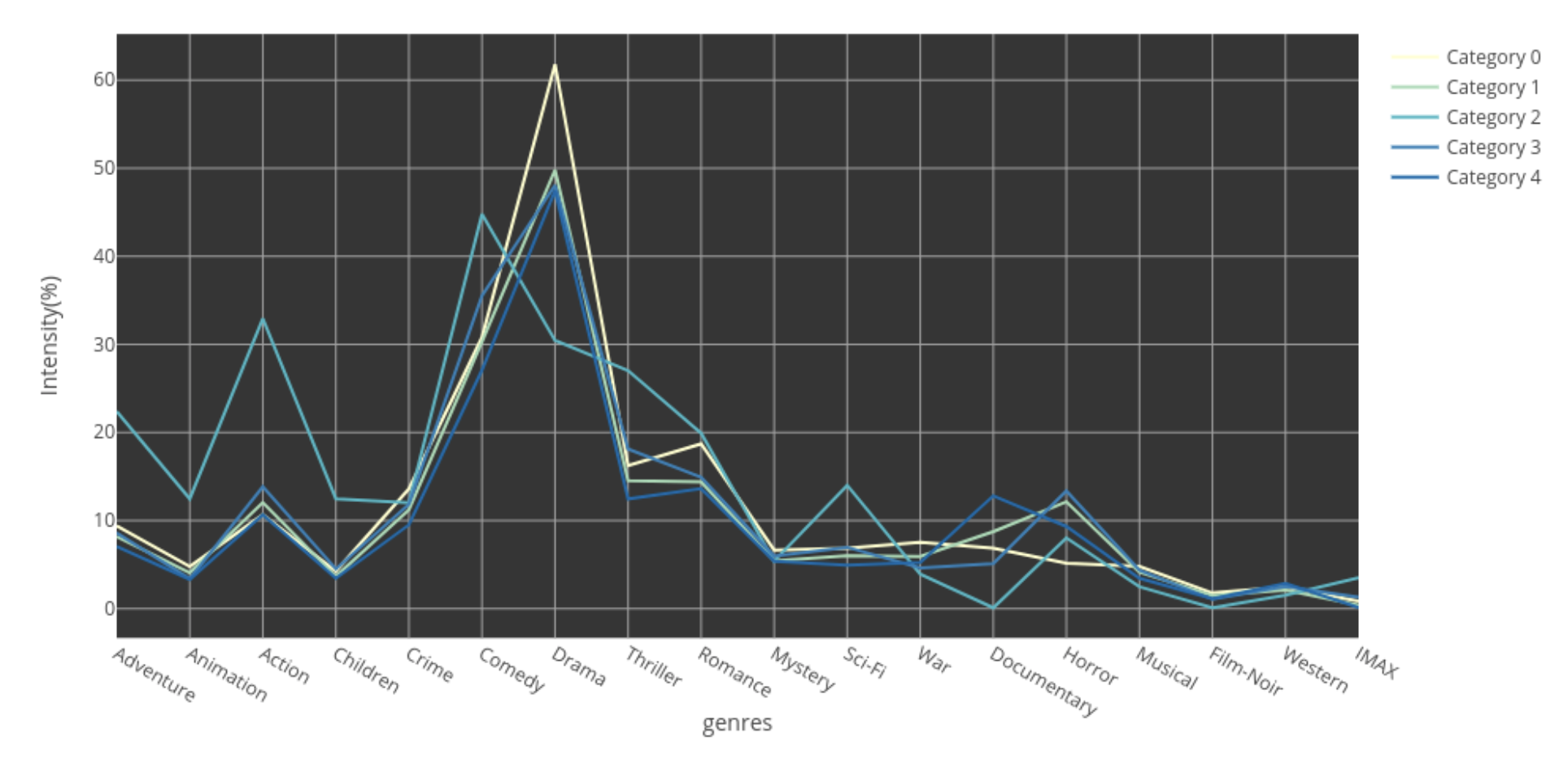 Figure 2. Percentage of genres in each estimated category
Figure 2. Percentage of genres in each estimated category
Then I plot another scatter plot showing the number of rating people. I finally find the problem: some movies were rated by a few people (the gray area is the rating count lower than the others), so it is hard to learn its behaviors by the machine.
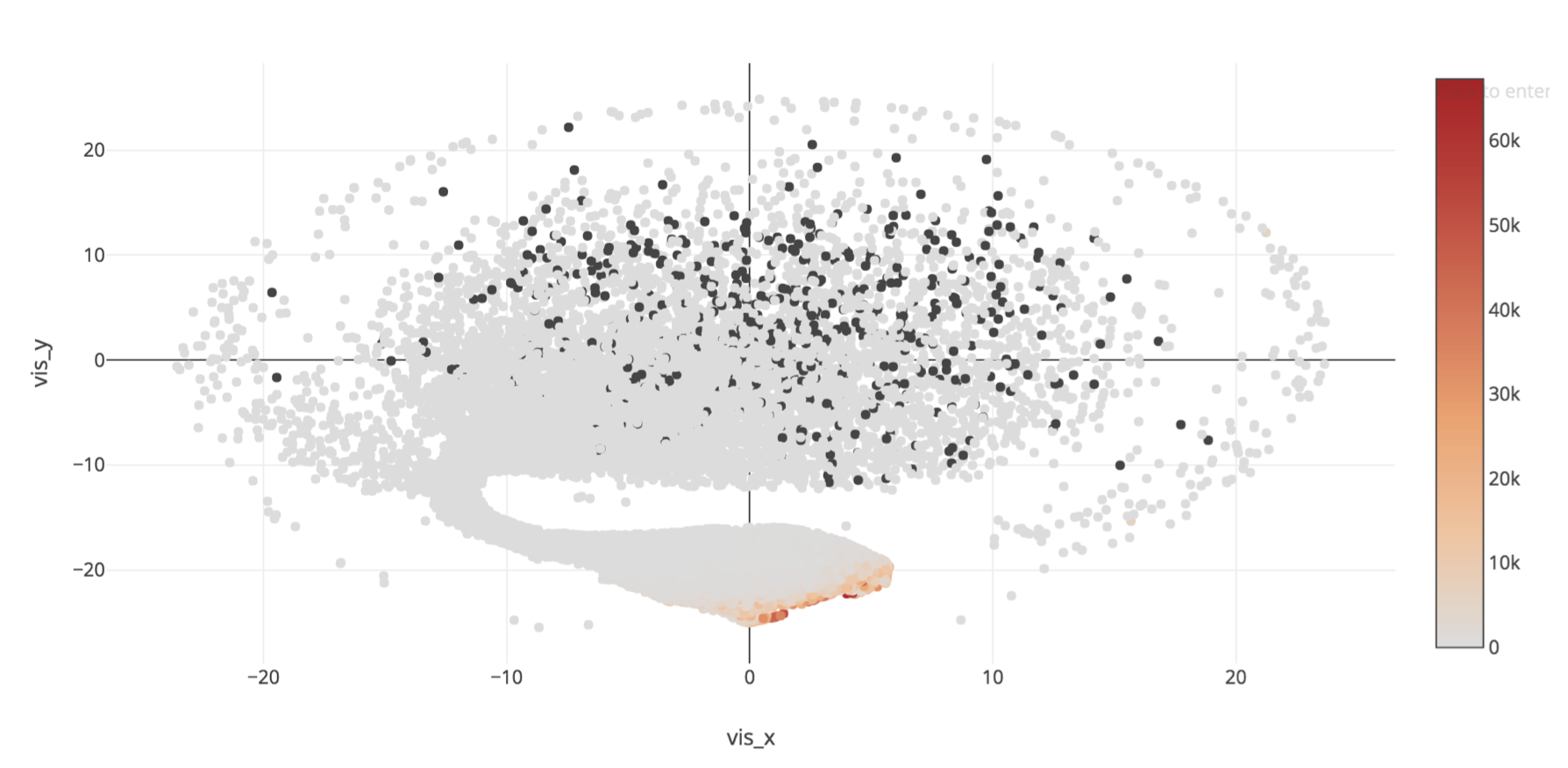 Figure 3. Rating Count of each Movie
Figure 3. Rating Count of each Movie
After removing the movie which rating count less than 1000, the plot becomes:
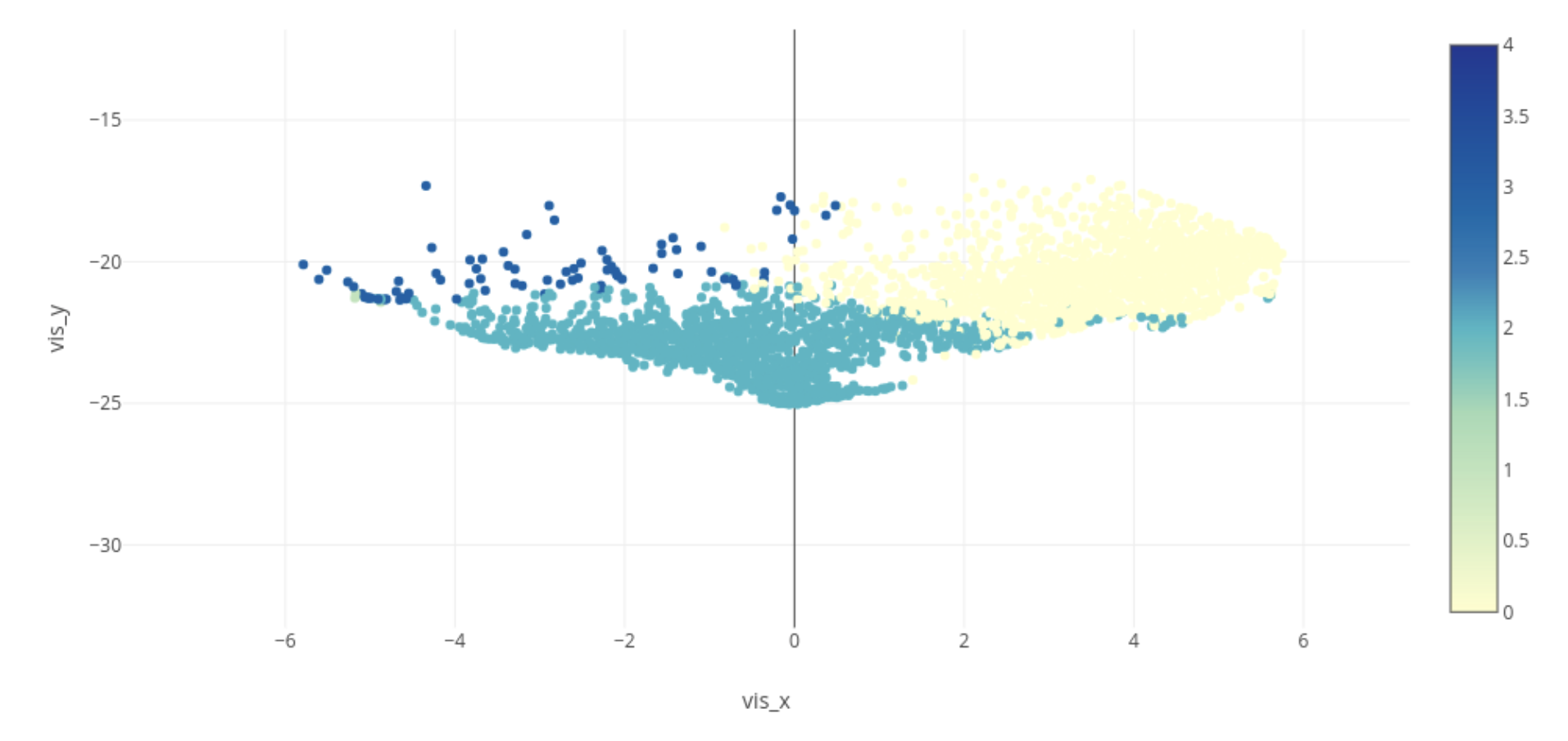 Figure 4. K-means Estimated Categories This figure extracts the movies with higher rating counts and is labeled by their estimated Category number.
Figure 4. K-means Estimated Categories This figure extracts the movies with higher rating counts and is labeled by their estimated Category number.
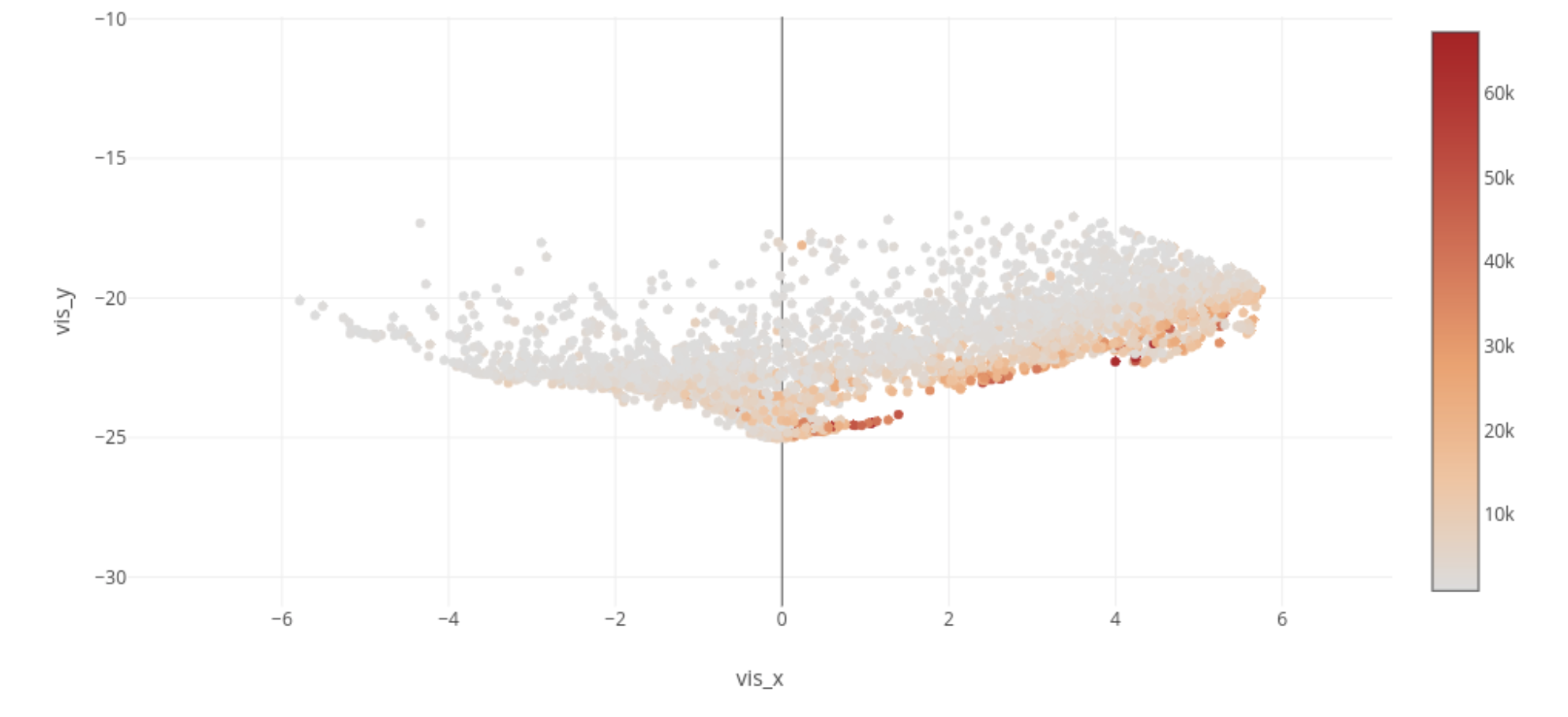 Figure 5. Number of Rating People This figure is labeled by its rating count. (Ranging > 1000)
Figure 5. Number of Rating People This figure is labeled by its rating count. (Ranging > 1000)
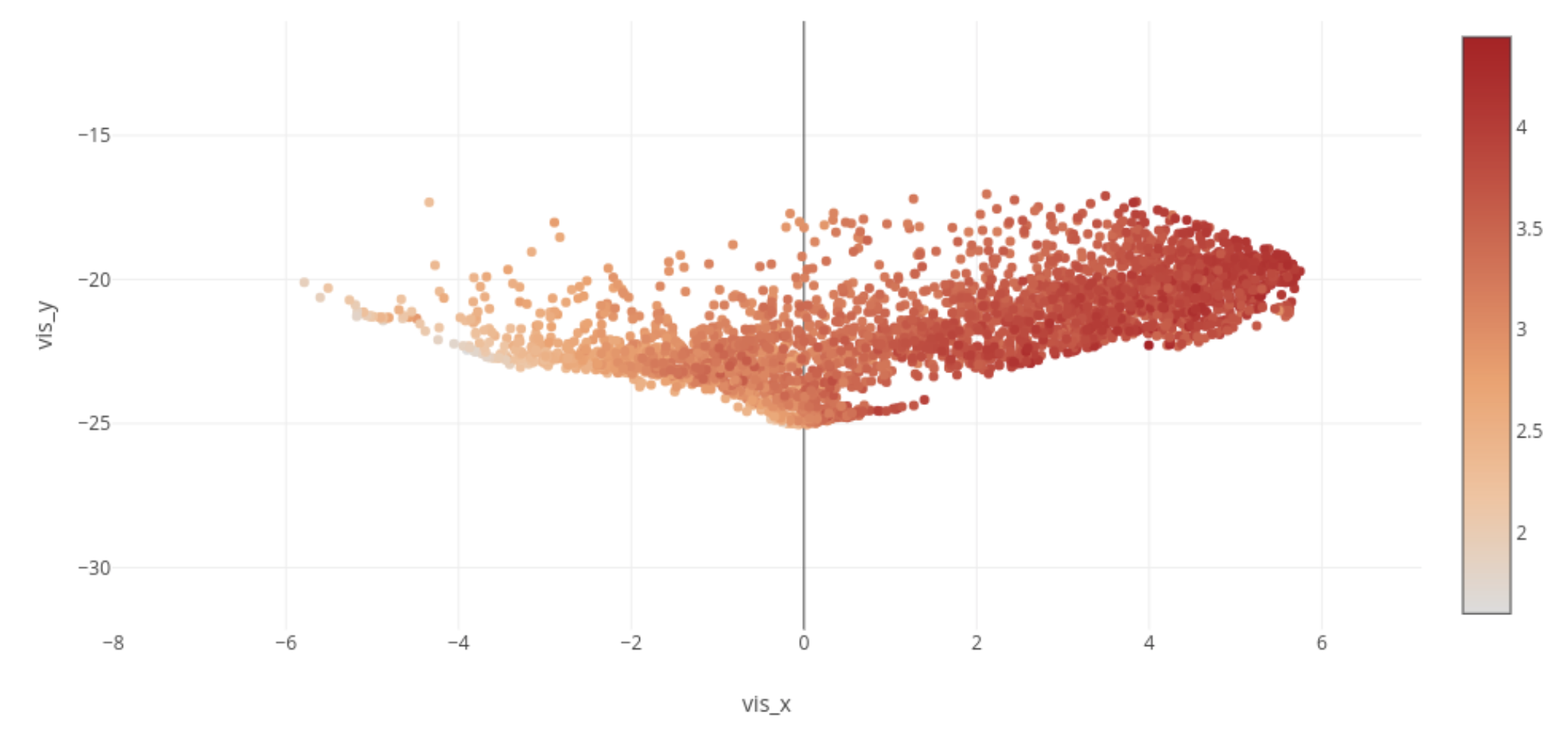 Figure 6. Movie Ratings This figure is labeled by movies’ real ratings. (Ranging 0-5)
Figure 6. Movie Ratings This figure is labeled by movies’ real ratings. (Ranging 0-5)
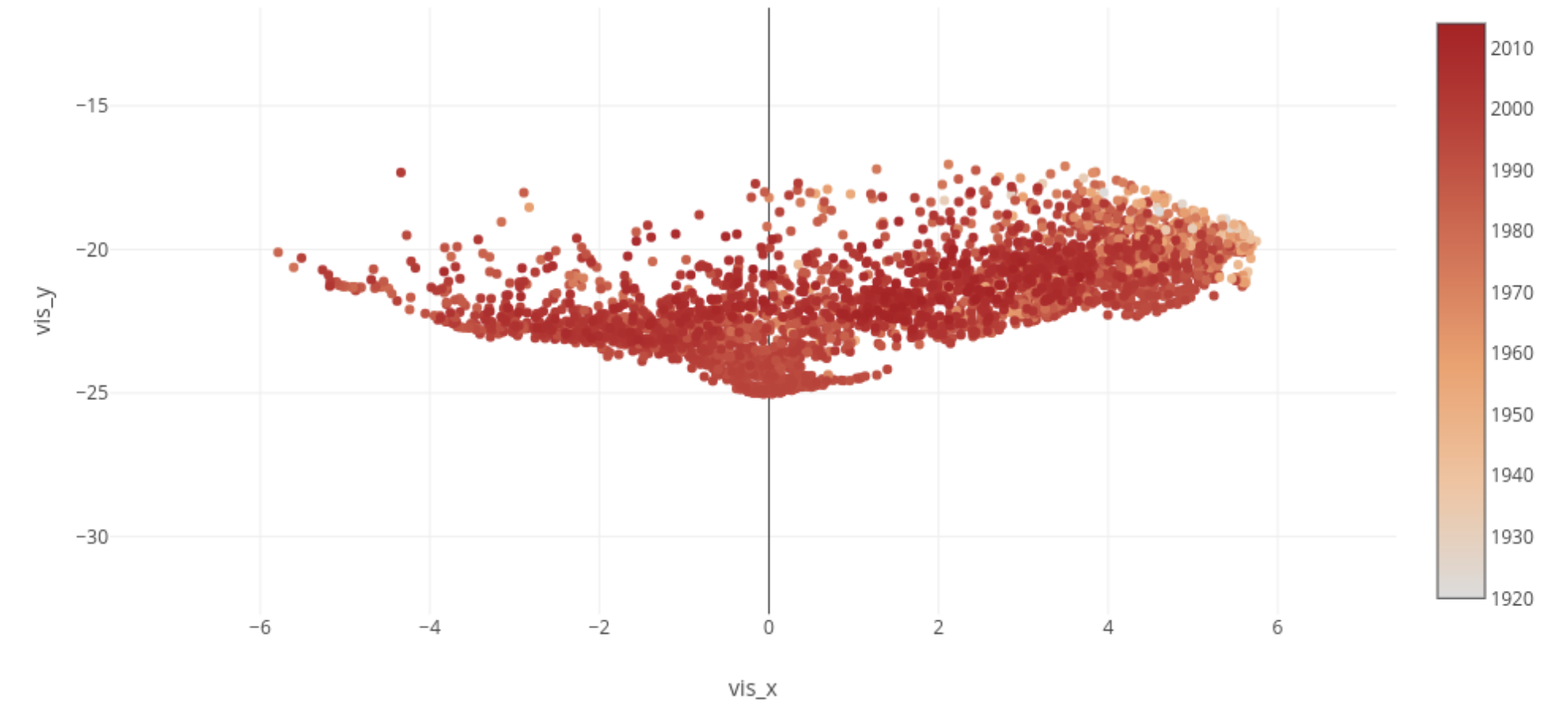 Figure 7. Movie Produced Year This figure is labeled by movies produced a year.
Figure 7. Movie Produced Year This figure is labeled by movies produced a year.
Analysis & Conclusion
We can infer some conclusions through these figures:
- The movie embedding vectors can be plotted to show some information:
- It shows the relationship between movies and their gradient.
- In figure 5, the closer to bottom, a movie is more popular (more rating count).
- In figure 6, the closer to the right-hand side, a movie is more recommend by people (higher rating).
- In figure 7, the closer to the upper right corner, the movie is older but is it not obviously.
(Note that the training process only uses user ID, movie ID, and their ratings).
- It shows the relationship between movies and their gradient.
- The K-means categories can be interpreted as:
Category 0: the highest rating score ones and its main genres is Drama.Category 2: the most popular ones (it may happen because the latest movies were rated by users more accessible to rating systems.), and its main genres are Adventure, Action, Comedy, Sci-Fi.
- If we want to make a recommendation system, we can convert the movie/user/rating records into movie embedding vectors. The more similar between two movie vectors, the more possible that these two movies behave similar patterns to users. Additionally, we can search recommended movies by the number of ratings (In figure 5, the downside direction) and ratings (In figure 6, the right direction).
Future works
- Analyzing users embedding layers as doing with movies embedding layers.
- Using a rating timestamp to see that people watch movies in what order.
- Finding out what kind of movies or what kind of users are more predictable.