Video Caption Generation
Task Description
- Given a short video, predict the corresponding caption that depicts the video
Model
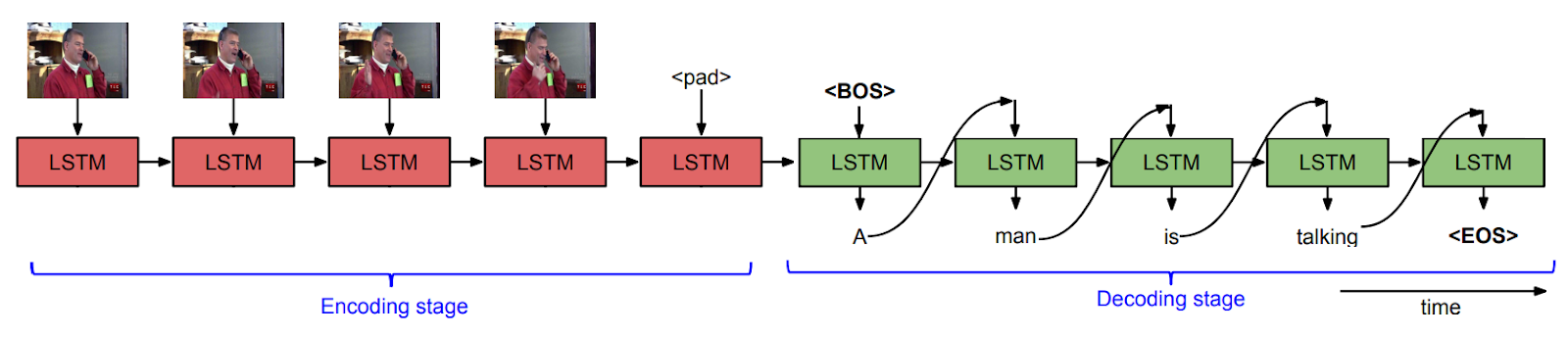
- encoder + decoder
- uni-directional LSTM
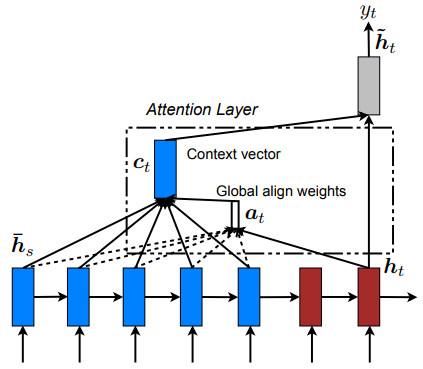
LuongAttention: Allow model to peek at different sections of inputs at each decoding time step
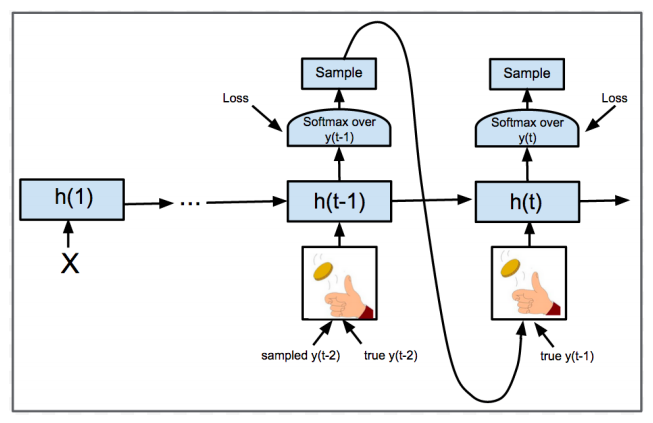
ScheduledEmbeddingTrainingHelper: To solve “exposure bias” problem, When training, we feed (groundtruth) or (last time step’s output) as input at odds
Evaluation
- BLEU@1:
$\text{BP=}\begin{cases} 1 & \text{if } c > r \newline e^{1-r/c} & \text{if } c\leq r \end{cases}$
$\text{Precision = correct words / candidate length}$
$\text{BLEU@1 = BP}\times \text{Precision}$
- Attention:
| without attention model | LuongAttention | BahdanauAttention | |
|---|---|---|---|
| $\text{BLEU@1 score}$ | 0.5994 | 0.6059 | 0.5867 |
- Schedule sampling:
| without schedule sampling | ScheduledEmbeddingTrainingHelper | |
|---|---|---|
| $\text{BLEU@1 score}$ | 0.5994 | 0.6478 |
- Attention + Schedule sampling: $\text{BLEU@1 score = 0.6510}$